Search Results for: multiple fruit

Multiple fruit
Definition noun, plural: multiple fruits A type of fruit that develops from the ovaries of many flowers growing in a cluster... Read More
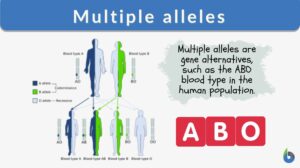
Multiple alleles
Alleles are the pairs of genes occupying a specific spot called locus on a chromosome. Typically, there are only two alleles... Read More

Fruits, Flowers, and Seeds
Flowering plants grow in a wide variety of habitats and environments. They can go from germination of a seed to a mature... Read More
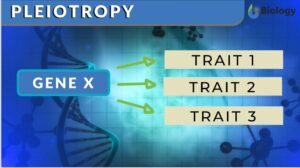
Pleiotropy
Pleiotropy Definition When one single gene starts affecting multiple traits of living organisms, this phenomenon is known... Read More
Aggregate fruit
Definition noun A type of fruit that develops from a single flower of many simple pistils. Supplement Examples are... Read More
Simple fruit
Definition noun, plural: simple fruits A type of fruit that develops from a single or compound ovary with only one pistil... Read More
Accessory fruit
Definition noun, plural: accessory fruits A fruit that contains tissue derived from plant parts other than the... Read More

Sex-linked trait
Definition of Sex-Linked Traits A sex-linked trait is an observable characteristic of an organism that is influenced by the... Read More


Positive feedback
Positive Feedback Definition Each mechanism of the body like temperature, blood pressure, and levels of specific nutrients... Read More

Endoplasmic reticulum
Endoplasmic Reticulum Definition The endoplasmic reticulum is a membrane-bound organelle in cells of eukaryotic cells... Read More


Humans are Omnivores – Evidence
A number of popular myths about vegetarianism sprung with no scientific basis. One example of such a myth is that man is... Read More

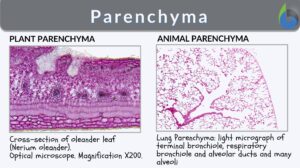
Parenchyma
Parenchyma Definition What does parenchyma mean? Let's define the word "parenchyma". Most of the functional tissues in... Read More

How cell fixes DNA damage
DNA repair strategies DNA is crucial to life. It carries the fundamental blueprint for the proper functioning of a cell.... Read More
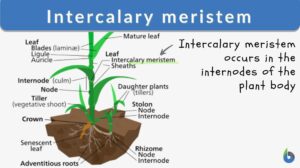
Intercalary meristem
The basic structural framework of plants is composed of different types of tissues. Based upon the capacity to divide, the... Read More
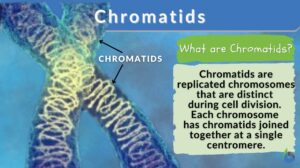
Chromatids
Chromatid Definition Chromatids are found inside our cells. Chromatids are condensed chromosomes distinguishable during... Read More

Chronobiology
Chronobiology Definition Chronobiology is a branch of biology that studies time-related phenomena (e.g., biological... Read More
Galacto-oligosaccharide
Definition noun plural: galacto-oligosaccharides ga·lac·to·ol·i·go·sac·cha·ride An oligosaccharide made up of... Read More